
Key Points
- Don't make grand statements about a digital presence based on isolated examples
- Test content hypotheses to confirm or disprove them
- See the distribution of content problems to better understand and address them
What is a content hypothesis?
A content hypothesis is:
A statement about your content...
...that can be tested...
...for each piece of content...
...and aggregated meaningfully across your digital presence.
An example content hypothesis would be "Walls of text are a pervasive problem across the site." In this case:
It is a statement about your content.
It can be tested, once we define for example that a wall of text is over two thousand words on one page.
It can be tested on each page of content.
It can be meaningfully aggregated across your digital presence, for example by looking at the percentage of pages that have the issue
Isolated examples are not enough to justify our analysis
We usually only really understand a small portion of a digital presence. For instance, if you work on a specific section of a site, then of course you understand that section. If that is the case, then you may be able to make grand statements about your content, like the fact that the content is mostly old content.
But, especially for larger digital presences, no one person can visit a high enough percentage of the pages to be able to confidently make statements about the content writ large. And, as the size gets larger and larger, giving examples becomes less and less persuasive in making general statements.
We need a more effective and systematic way of making insightful and provable observations about our content.
Hypothesis analysis goals: summarize, understand patterns, and list
In the end we want to summarize whether the hypothesis is true or not. To fully support whether the hypothesis is true, we need to have a list of the content and what content the hypothesis is true for. To help us get a richer understanding of the situation, and how to correct the issue, we need to also understand the pattern(s) of the problem.
Summarize: the desired end result to test the hypothesis
We want a conclusive, straightforward result for our hypothesis: we would like to know if the content hypothesis is true. Continuing with the example we started above, let's say our hypothesis is "Walls of text is a pervasive problem across the site." If only 1% of the pages have this issue, then we can say that hypothesis is false.
Understand patterns: helping to understand and develop a plan to resolve the issue
If a problem is isolated (like only the top level pages), then it can be dealt with in an isolated, manual manner. If a problem is pervasive, then other approaches would be required to resolve it. For instance, you may seek automated approaches to resolving the content issue (like walls of text), and if automated approaches to resolve the issue are not possible then it is a much bigger manual problem to deal with.
Another hypothesis might be "We can rely on Country ISOCODE values to expose information by country." Let's say your CMS allows you to specify the Country ISOCODE, and you know that the recent pages in the English section are tagged to that. But you don't really know if pages are actually assigned to this value.
Ideally we want to see the distribution of where the hypothesis is true and not. For instance, here is the distribution of where content has been tagged to ISOCODE (in green) across the site sections of a site:
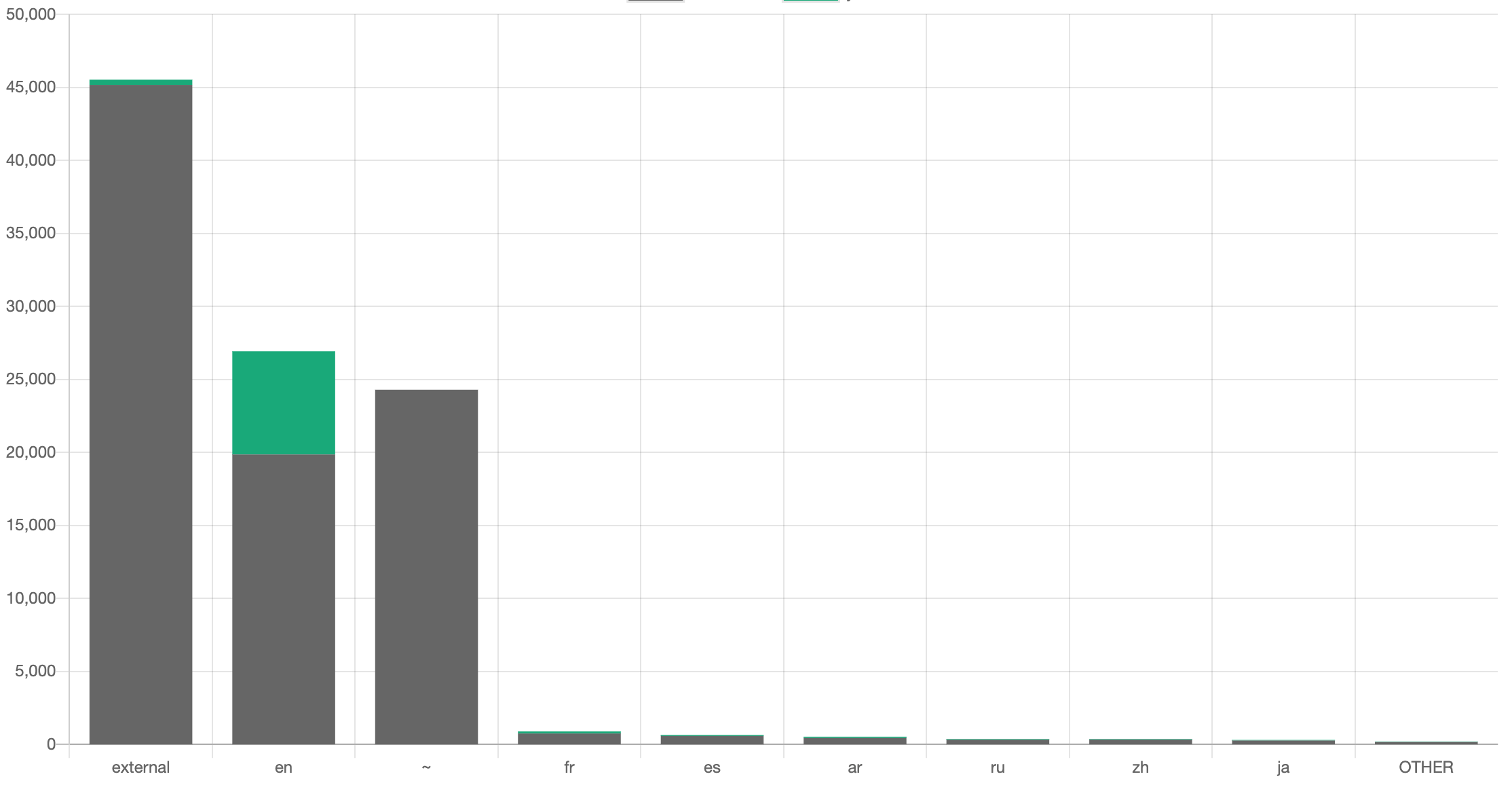
Seeing the distribution of where the problems are (where the most gray is in the graph above) may help us understand the problem, strategize about how to fix it, or even refine the hypothesis. For instance, we may realize that it's ok that the "~" directory of the site is not tagged to Country ISOCODE, since none of that information is country-specific.
The list of content
By testing every piece of content, we have another advantage: we then have a list of content that needs to be resolved, rather than having to inspect every piece of content again when it is time to execute the changes (see Decide. Don't Inspect).
So we would wind up with a list like this (probably with more fields):
| URL | Has ISOCODE? |
|---|---|
| /external | No |
| /external/chad | Yes |
| /en/countries/chad | No |
| /en/countries/cameroon | Yes |
If we decide that content needs to be improved by tagging to country then we would now have a list of the content that requires those changes.
How do you test a content hypothesis?
The steps of testing a content hypothesis are straightforward.
Avoid making a general statement about a digital presence from some examples.
Clearly state the hypothesis.
Determine how you will broadly test the hypothesis.
Test the hypothesis across broadly.
Look at the distribution.
Determine if the hypothesis has been proven or disproven.
Clarify / refine the hypothesis and repeat.
Perhaps the most difficult aspect of testing a content hypotheses is how to test broadly across an entire digital presence. Here are three ways of doing this.
Manually
This is the approach most of us would probably take, by manually going through all the content to test the hypothesis. This is problematic for many reasons: a) it's difficult to iterate (let's say midway through manually checking 10,000 pages that you change the exact definition of the hypothesis!), b) it's difficult to be consistent, and c) it's inefficient. That said, if you are forced into this option then one optimization to consider is randomizing what you are reviewing manually (and not just walking through a spreadsheet that is probably organized by section) — that way you may be able to see the patterns more quickly.
Automatically with a standard crawler
Screaming Frog has the ability to scrape out patterns from a site, which allows you to generate a list of content along with the pattern extracted. Then you can use Excel or some other tool to chart distributions.
Automatically using Content Chimera
Content Chimera is built for testing content hypotheses:
It saves a cache of your entire digital presence, so you can quickly test new hypotheses — and without hammering the website servers unnecessarily
For any pattern that's extracted, it automatically loads additional fields into the inventory to help in analysis and charting — for instance, if you are scraping ISCOCODE then it captures a simple "Has ISOCODE" and "ISOCODE count" that are often useful (along with other fields)
It has a powerful mechanism for users to specify patterns to extract from the website (or, for that matter, other resources)
It charting it allows the user to click on a chart to randomly sample
It immediately allows you to show the distribution of where problems exist
You can then define rules to help you understand the effort to resolve content issues