
Key Points
- The knee-jerk approach is to sample or selectively analyze content, but that often blocks the broad changes that deliver the most value.
- A comprehensive approach analyzes every page, enabling pervasiveness views, outlier detection, and iterative, exploratory analysis.
- An indexed (RAG) approach fits when you don't know whether something exists and want to query all content on demand.
- Comprehensive analysis requires automation — data pipelines and a data lake — since "raw" chatbots can only do selective analysis.
Whenever we are analyzing a website — whether for content, IA, AI, or otherwise — we have a decision to make: is it sufficient to sample the content or do we need to analyze all the content?
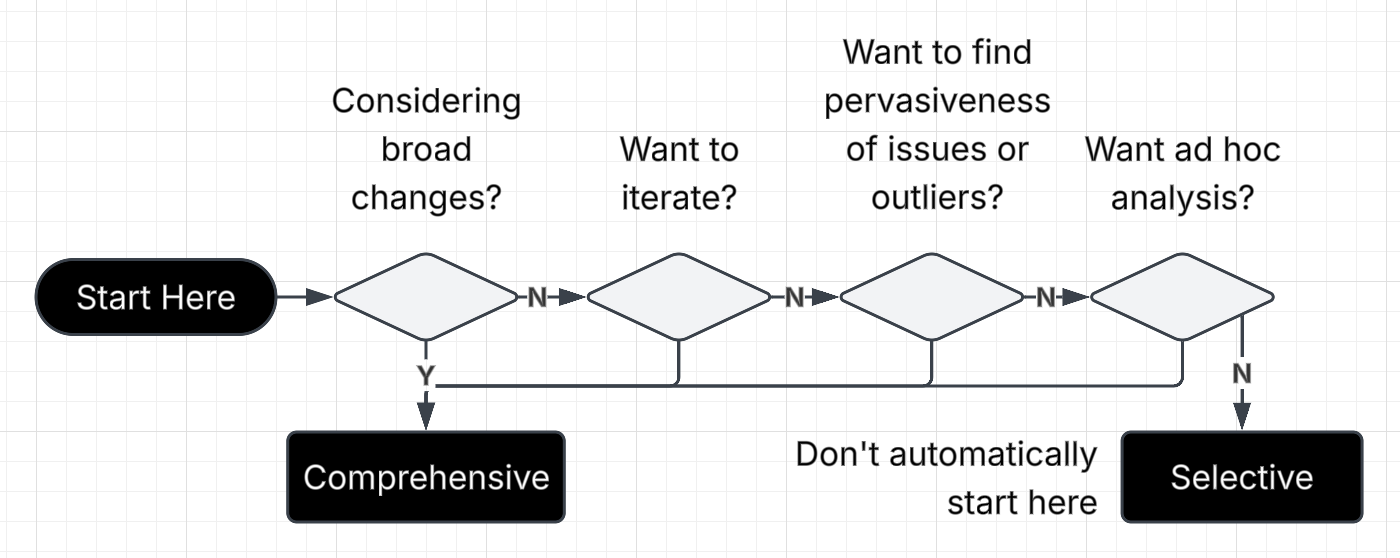
The knee-jerk reaction is of course to sample the content (or somehow restrict the problem, such as analyzing just a small section of a site) or otherwise be selective in the analysis (such as only analyzing a section of the site).
My main concerns about this perennially favored approach:
Everyone falls into this mode even when it's not appropriate for the analysis task.
It makes it less likely for broad change which is often the type of change that would result in the most value.
Comprehensive
In the comprehensive approach, we look at all the content. For instance, we look may look at the reading level across all content. Then we can look for the pervasiveness of reading level or slice/dice it be site, site section, content type, etc.
If we consider a simplified sitemap (of course a real site would be far wider and deeper), conceptually we would have a reading level score for every piece of content:
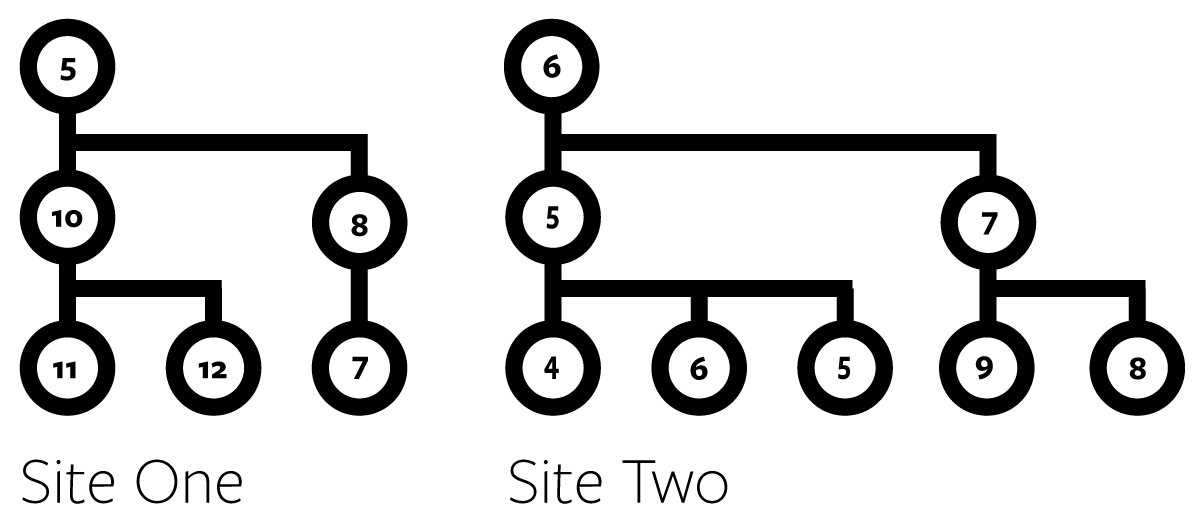
The advantages of the comprehensive approach:
You have analysis on every page
It sets the stage of iterative, exploratory analysis (you just tweak and rerun the analysis)
Ability to see how pervasive issues are
Ability to find outliers and prioritize
Ability to have a baseline to evaluate while improving over time
We can then do things like this, which we did for a large organization during a search improvement project to see what metadata was available for what content types (to see things like whether bios could actually effectively be queried by country for example):
This approach does require an automated approach (except at a small scale).
Selective
The clear advantage of the selective approach is simplicity (and cost, when done manually).
In this case, we might restrict the analysis to one part of the site and then manually set values, for instance for reading level:
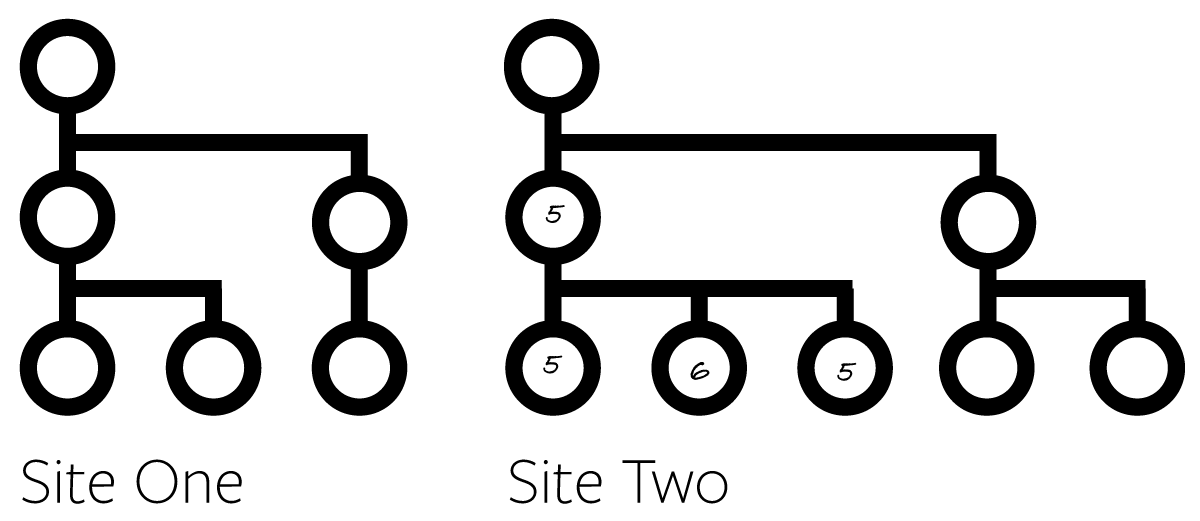
The selective approach makes sense, even outside of any implementation restrictions, in some cases:
Extremely high confidence that you: a) know the groups of content and b) that samples of that group represent the analysis you need. For instance, if you know the different content types, you know that all the content of each content type is rendered by the same template, and you know that what you are analyzing can cover only those common components — like if you are only evaluating the top level of breadcrumbs and the top level of the breadcrumbs are rendered the same for all pages of a particular content type.
You literally will only be making changes to a selection of the content, so that's really all you need to check.
You are only trying to get an overall feel of a situation, just scanning for obvious big issues etc.
Of course you may be forced to use the selective approach if you don't have the experience or technical ability (or funds for a tool like Content Chimera) to implement a comprehensive analysis.
Indexed
Sometimes you don't know if something exists or not. In this case, the indexed approach works. We all know old school search indexes, but now we have semantic encodings and vector databases to allow RAG searches. So in this case we:
Create an INDEX of all the content.
Run a query against that index to find the most relevant content.
Do further analysis against the relevant content.
The advantages of this hybrid approach:
Once set up, you can ask ad hoc questions whenever you want.
You can query in natural language.
If we simplify a vector database to three dimensions to visualize things, we can basically group the semantic "nearness" of information:

This means that we have indexed all the content of a site:
Tools and Approaches
Now we come to a harsh truth: "raw" chatbots can only do selective analysis. In order to do comprehensive analysis you need two things:
A method to run data pipelines, to crawl, scrape, run LLM analysis efficiently, and more
A data lakehouse (or, for limited analysis, perhaps a simple database) to store the actual data
Why are these two things needed? Because a chatbot cannot look at much data at once. You need to put the data someplace that is efficient with a lot of data, and then let the chatbot do things that it's good at (like querying databases). Similarly, a chatbot is not built for complex, long-running jobs (but is fine at calling tools that do).
| Selective | Indexed | Comprehensive | |
|---|---|---|---|
| Manual | ★★★ | ||
| "Raw" chatbot | ★★★ | ||
| RAG search infrastructure | ★★★ | ||
| Chatbot or app with pipelines and data lake | ★ | ★★★ |
Questions and how they are answered
| Comprehensive | Selective | Indexed | |
|---|---|---|---|
| Extent of digital presence analyzed | All | Some | All |
| Specific content reviewed at query time | All | Some | Some |
| Update effort | Low | High | Very Low |
If we simplify this to a traditional spreadsheet inventory to compare of comprehensive, selective, and indexed analysis:
Comprehensive analysis will have a row for every page of the digital presence and a column for all the fields. If we automate, this means that we can go through and generate values for every page and field (and we can tweak and iterate). When we do a query (like "what is the average crawl depth?") that query goes against all pages.
Selective analysis will have a row for those pages in the analysis and a column for all the fields. Usually this would mean that each row would be filled in manually. So, although our query might go through all our rows in the analysis (like "what is the average actionability rating?"), we are only querying against some of the pages of the whole digital presence. If we want to iterate on the analysis, it's going to be time-consuming to go through the content again.
When we create an index, we can do so across all the pages. When we query, we would find the closest pages. So then at query time ("what is the privacy policy") we would look at those closest pages, for instance potentially finding that there are multiple privacy pages. It is very easy to update the index.